本文最后更新于 2025-03-18T14:25:39+00:00
模型选择与显存估算 在部署LLM时,模型尺寸直接影响推理的速度与硬件需求,通常需要平衡考虑以下因素:
1. 精度与速度的权衡
半精度推理(FP16/BF16) 低精度量化
2. 模型规模与资源成本平衡
性能规律
以下为常见的量化方式与显存占用估算(仅权重)
模型名称
参数量
模型精度
显存占用 (GB)
DeepSeek-R1-671B
671
FP16
1610.4
671
FP8
805.2
671
Q8_0
805.2
671
Q5_K
553.58
671
Q4_K
452.93
671
Q3_K
345.98
671
Q2_K
257.92
671
IQ2_XXS
207.34
671
IQ1_M
176.14
671
IQ1_S
157.01
DeepSeek-R1-70B
70
FP16
168
70
Q6_K
68.91
70
Q8_0
84
70
Q5_K
57.75
70
Q4_K
47.25
70
Q3_K
36.09
70
Q2_K
26.91
在大模型运行过程中,显存占用可分为以下两部分:
1. 静态占用(多会话之间共享):
2. 动态占用(每会话独立):
总结上述,部署大模型总显存需求: 总显存 = 静态占用 + 动态占用
具体计算公式(KV-Cache共享):
$$
\text{Total VRAM} = \underbrace{P \times d}_{\text{模型参数}}
+ \underbrace{C}_{\text{框架开销}}
+ \underbrace{(2 \times s \times l \times h \times d)}_{\text{KV-Cache}}
$$
具体计算公示(KV-Cache不共享):
$$
\text{Total VRAM} = \underbrace{P \times d}_{\text{模型参数}}
+ \underbrace{C}_{\text{框架开销}}
+ \underbrace{(2 \times s \times l \times h \times d)}_{\text{单个会话KV-Cache}} \times S
$$
变量说明:
( P ): 模型参数量(单位:Billion)
( d ): 单参数字节数(FP16=2,INT8=1)
( C ): 框架固定开销
( s ): 序列长度(输入+输出tokens)
( l ): Transformer层数
( h ):注意力头维度(head_dim)
( S ):会话数
由上述公式中可以看到,在模型一定的情况下,显存占用的大小还与上下文长度与会话数有关。
环境准备 提前做好如下准备:
每个节点最好有IB网卡,如果没有IB网卡,最低也得需要10G互联
安装 Ubuntu 24.04操作系统
根据设备情况,安装NVIDIA 显卡驱动
挂载NFS共享文件存储
安装Docker并配置好加速器
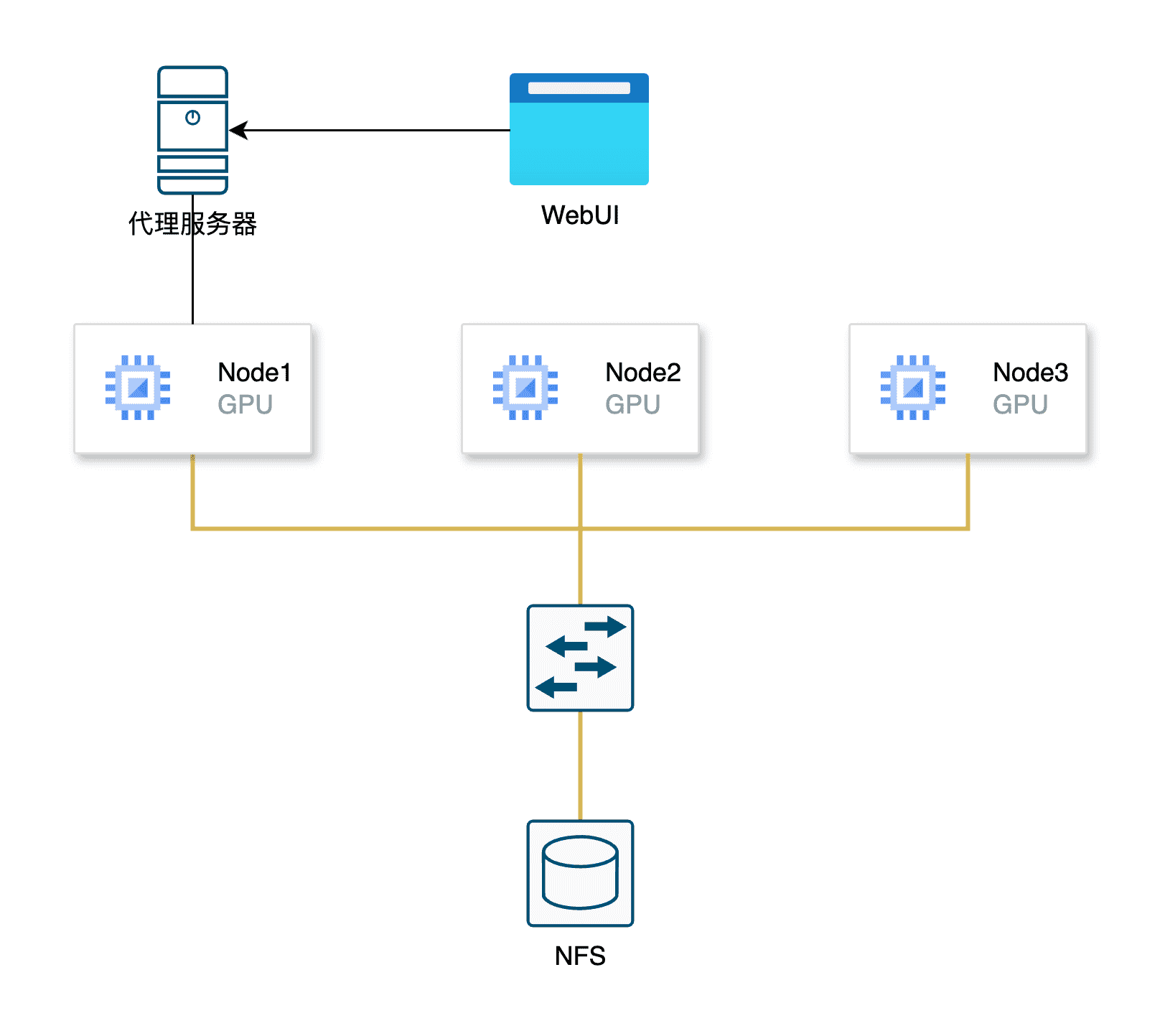
此处演示环境拓扑如下:
1 2 3 4 5 6 7 sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
2. 开始构建Docker镜像 首先Pull 下官方的镜像,截止本文编写时最新镜像标签为 0.7.3.
1 2 3 4 5 6 7 8 docker pull vllm-openai:0.7.3# 容器镜像比较大,稍微等待一会
开始编写Dockerfile 内容
创建一个工作目录 /opt/workspace,在目录下创建Dockerfile 文件,写入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 FROM vllm-openai:0.7 .3 ENV TZ=Asia/Shanghai \180 \1 WORKDIR /server COPY . . RUN apt-get update && apt -y install \ dos2unix tzdata vim tree curl wget \ && ln -sf /usr/share/zoneinfo/${TZ} /etc/localtime \ && echo ${TZ} > /etc/timezone \ && dpkg-reconfigure --frontend noninteractive tzdata RUN pip install ray[default]==2.40.0 --upgrade --force-reinstall RUN find ./ -type f -print0 | xargs -0 dos2unix && chmod +x entrypoint.sh ENTRYPOINT ["./entrypoint.sh" ]
其中GLOO_SOCKET_IFNAME、TP_SOCKET_IFNAME、NCCL_SOCKET_IFNAME 要改成你的节点互联网卡。注意:尽量保持各节点互联网卡名称一致,如果不一致请在运行时传入环境变量进行修改。
如果使用IB卡的话,请根据实际情况修改上述文件,当然这些环境变量也可在运行时传入。
接下来在工作目录下创建entrypoint.sh文件,并写入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #!/bin/bash "$1 " "$2 " echo "Starting Ray with ${NODE_TYPE} " echo "Head node address: ${HEAD_NODE_ADDRESS} " if [ "${NODE_TYPE} " == "head" ]; then echo "Starting head node..." head --node-ip-address="${HEAD_NODE_ADDRESS} " --include-dashboard=true --dashboard-host=0.0.0.0 --port=6379else echo "Starting worker node..." "${HEAD_NODE_ADDRESS} " :6379fi tail -f /dev/null
最后再在工作目录下创建启动脚本 start.sh ,并写入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #!/bin/bash if [ $# -lt 4 ]; then echo "Usage: $0 --model-path <model_path> --model-name <model_name> --max-model-len <max_model_len> --tensor-parallel-size <tensor_parallel_size> [--token <token> --model-type <model_type> --tokenizer-path <tokenizer_path>]" exit 1fi while [[ "$# " -gt 0 ]]; do case "$1 " in "$2 " ; shift 2 ;;"$2 " ; shift 2 ;;"$2 " ; shift 2 ;;"$2 " ; shift 2 ;;"$2 " ; shift 2 ;;"$2 " ; shift 2 ;;"$2 " ; shift 2 ;;echo "Unknown option: $1 " ; exit 1 ;;esac done ${GPU_MEMORY_UTILIZATION:-0.90} ${PORT:-8009} export VLLM_LOGGING_LEVEL=${VLLM_LOGGING_LEVEL:-WARN} ${LOG_FILE:-"/home/models/running.log"} if [[ "$MODEL_TYPE " == "gguf" ]] && [ -z "$TOKENIZER_PATH " ]; then echo "Error: tokenizer path is required for gguf model type." exit 1fi echo "Starting vllm serve with model: $MODEL_NAME , max model length: $MAX_MODEL_LEN " | tee -a $LOG_FILE if [[ "$MODEL_TYPE " == "gguf" ]]; then "nohup vllm serve $MODEL_PATH \ --served-model-name $MODEL_NAME \ --tensor-parallel-size $TENSOR_PARALLEL_SIZE \ --max-model-len $MAX_MODEL_LEN \ --gpu-memory-utilization $GPU_MEMORY_UTILIZATION \ --trust-remote-code \ --tokenizer-path $TOKENIZER_PATH \ --port $PORT " else "nohup vllm serve $MODEL_PATH \ --served-model-name $MODEL_NAME \ --tensor-parallel-size $TENSOR_PARALLEL_SIZE \ --max-model-len $MAX_MODEL_LEN \ --gpu-memory-utilization $GPU_MEMORY_UTILIZATION \ --trust-remote-code \ --port $PORT " fi if [ -n "$TOKEN " ]; then "$CMD \\ --api-key $TOKEN " fi "$CMD >> $LOG_FILE 2>&1 &" eval $CMD echo "vllm server started with PID: $PID " | tee -a $LOG_FILE exit 0
接下来构建镜像,在当前工作目录执行 sudo docker build -t ray-vllm:latest . 容器构建完毕后,我们需要将其分发到其他节点上,docker save [image id] >ray-vllm.tar ,在需要导入的节点上执行docker load < ray-vllm.tar ,然后重新 docker tag [image id] ray-vllm:latest一下即可。
3. 模型下载: 根据国内网络情况,推荐从魔塔社区进行模型下载,根据上述估算,选择适合自己的模型即可。
模型部署 1. 启动容器 1 2 3 4 5 Head 节点:
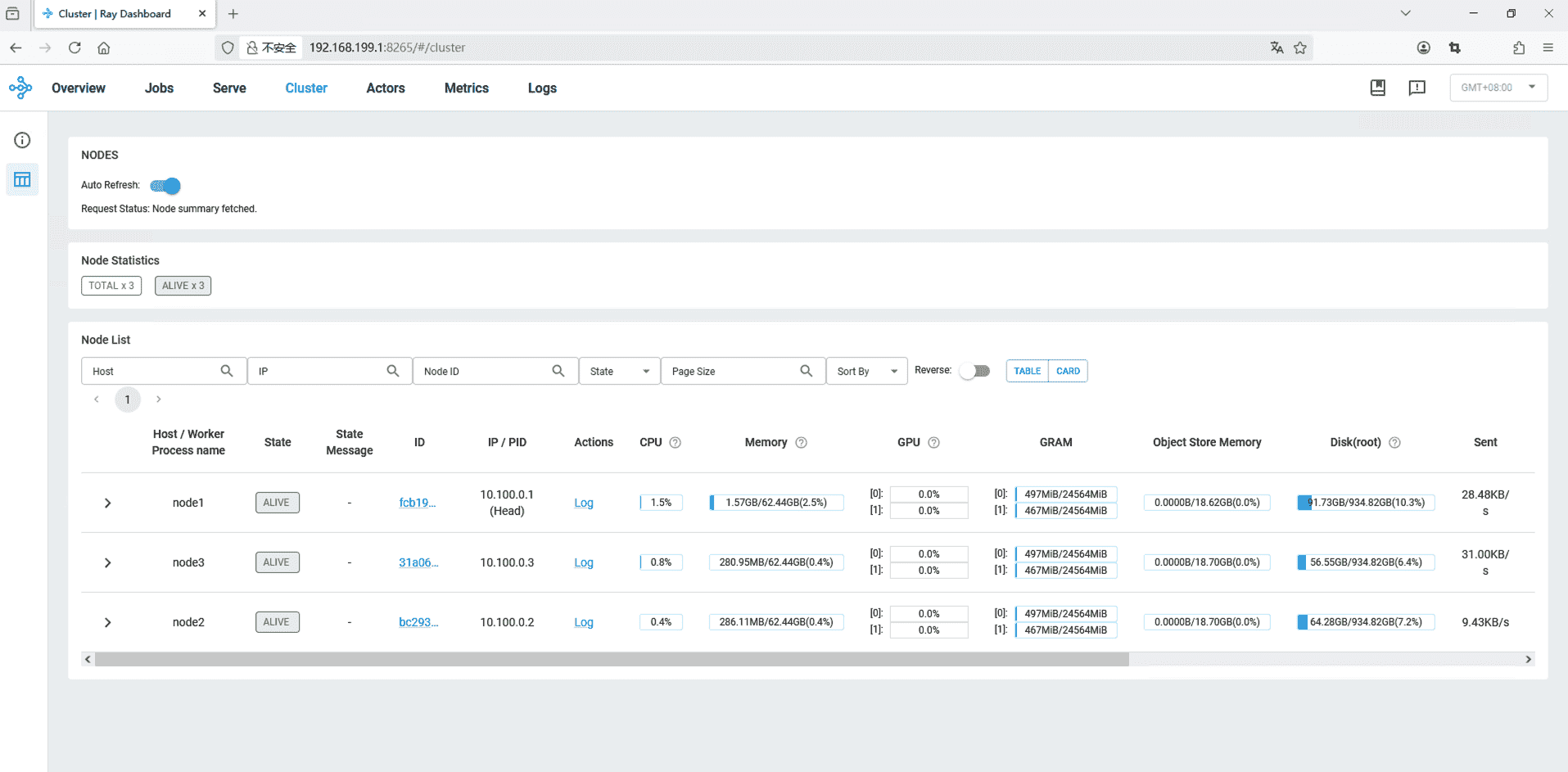
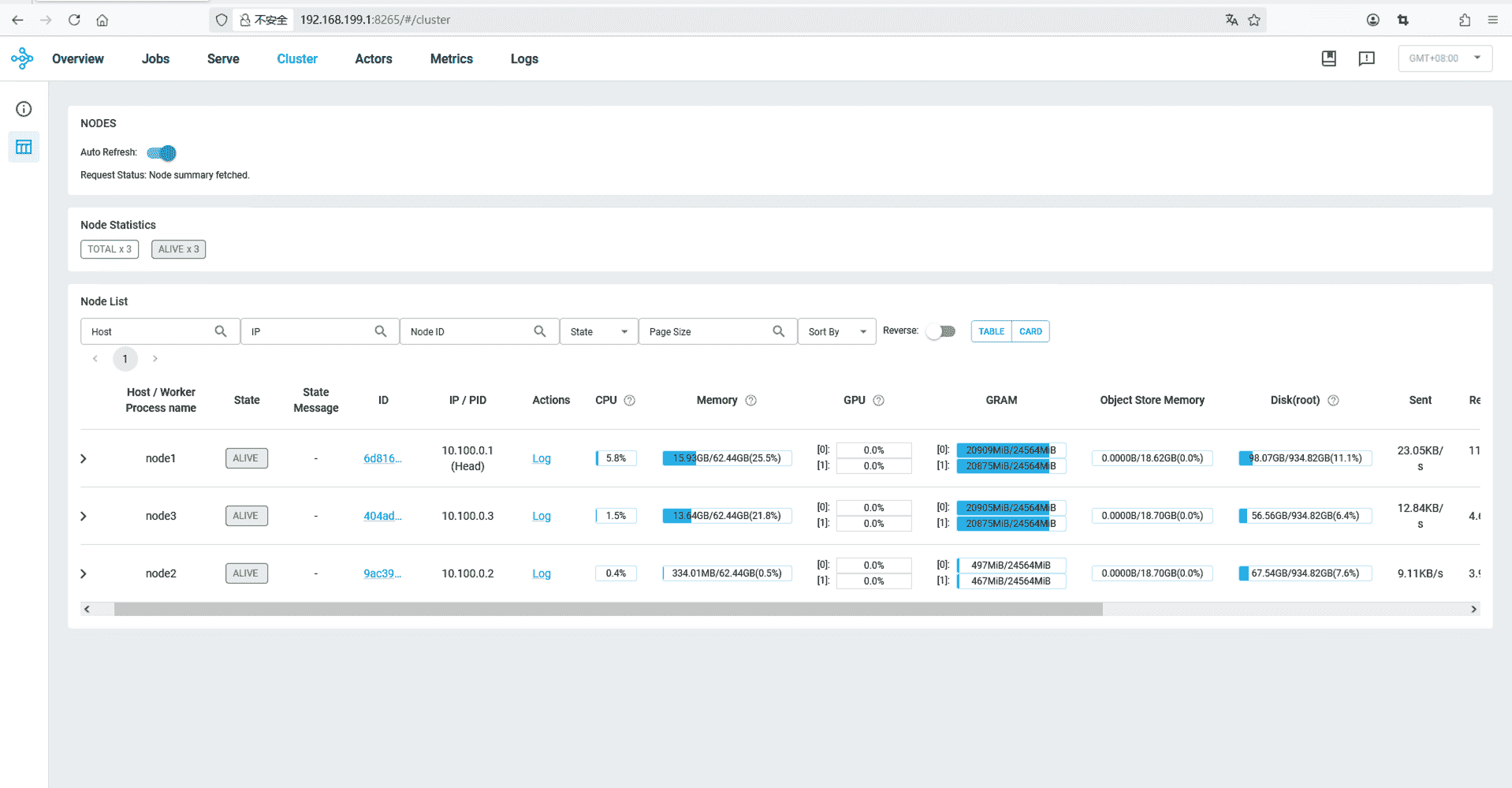
2. 启动模型 在容器启动完毕后,可以使用浏览器访问一下Head节点的8265端口,查看一下节点是否全部加入集群:
在节点全部加入集群后,在Head节点机器上,执行 docker exec -it ray-vllm bash 进入容器内shell。
根据实际情况将模型路径替换为你的路径即可,如果模型为gguf格式,需要指定模型类型为gguf,并且指定tokenizer-path, 根据资源情况适当调整模型上下文长度参数:max-model-len,tensor-parallel-size参数设定为显卡个数即可,我这里是6张卡,但是只能设定为4,可以思考一下是为什么? 可以根据需求是否设定API-KEY,如果需要设定API-KEY,那么需要指定 token参数,并在后边跟上 key。
1 2 3 root@node1:/server# ./start.sh --tensor-parallel-size 4 --model-path /home/models/QwQ-32B-GGUF/qwq-32b-q6_k.gguf --model-name QwQ-32B --max-model-len 32768 --model-type gguf --tokenizer-path /home/models/QwQ-32B-GGUF/
模型启动后,需要等待一会加载权重。
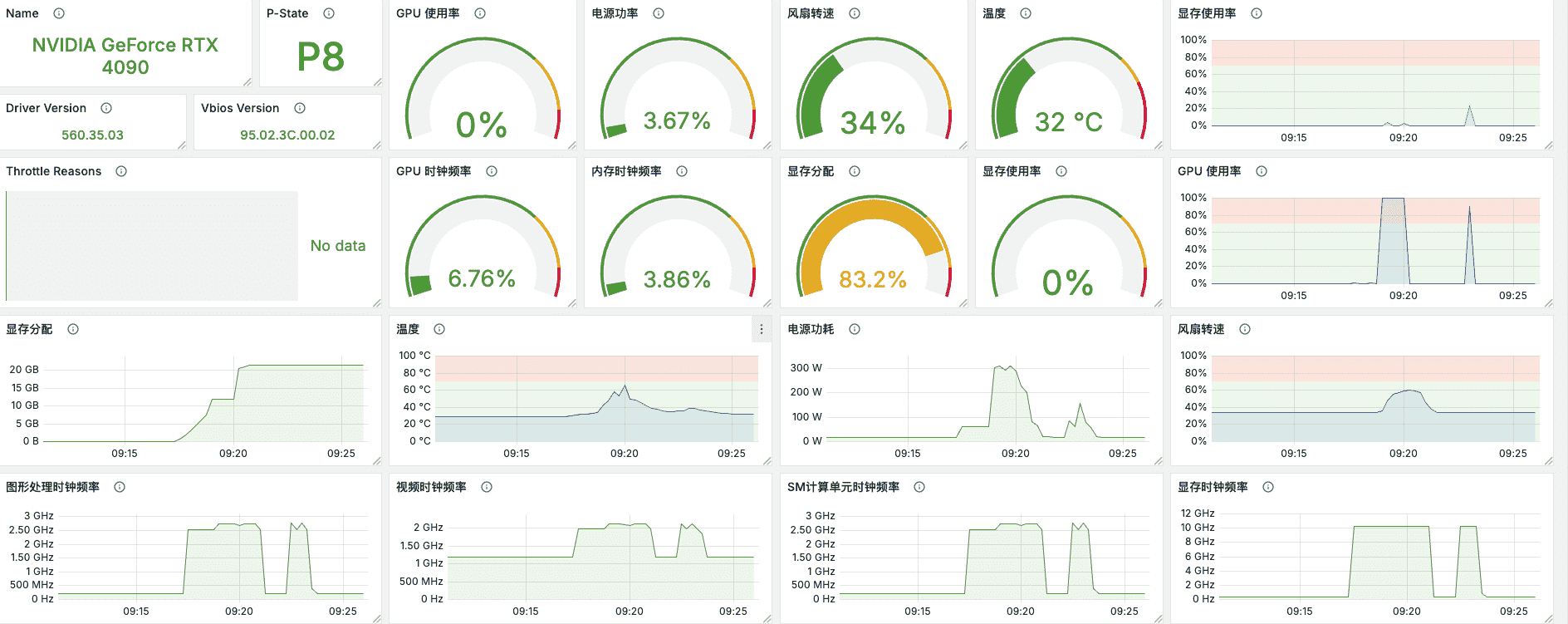
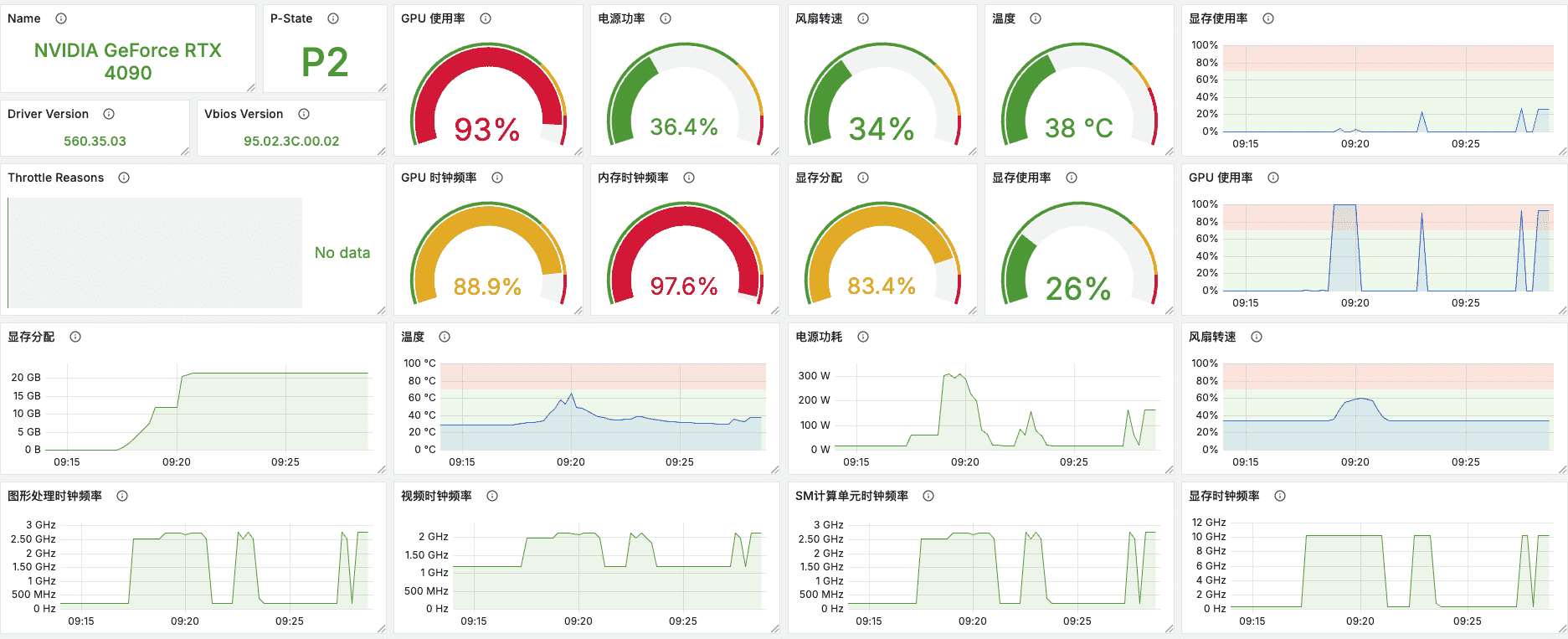
在不进行推理时,显卡功耗还是比较低的。
推理时,显卡功耗就比较高了。
模型测试 接入OpenWebUI 测试一下,效果还算可以。经过测试,QwQ-32B在使用4张RTX4090 进行推理时,32k上下文长度,可以支持5并发会话,速度可以达到20 token/s。