公共情报搜集爬虫
Photon是一种高效率的的网络爬虫,可从目标中提取URL,文件以及各类情报。其通过多线程大大加快数据提取进程。
主要特点
Photon提供的各种选项可以让用户按照自己的方式抓取网页,不过,Photon最主要的功能并不是这个。
数据提取
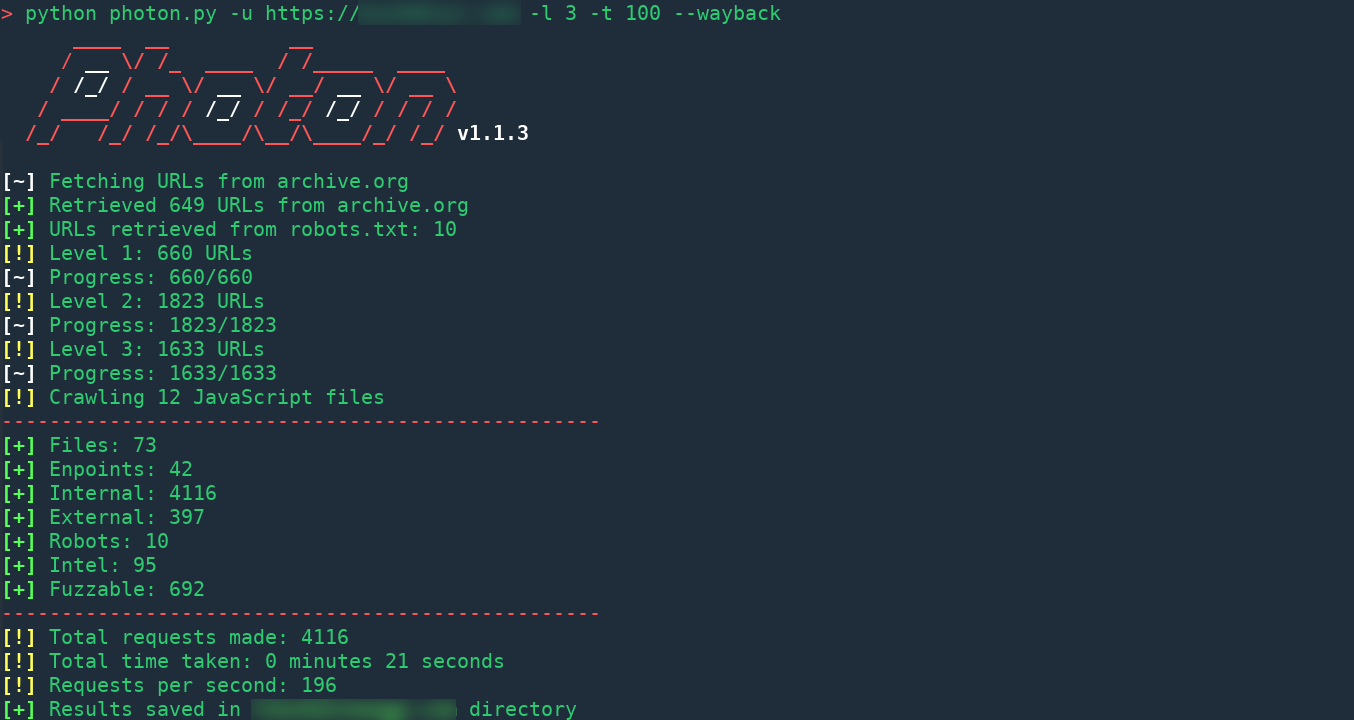
默认情况下,Photon在抓取时会提取以下数据:网址(范围内和范围外的)
带参数的网址(example.com/gallery.php?id=2)
情报(电子邮件,社交媒体帐户等)
文件(pdf,png,xml等)
JavaScript等文件
基于自定义正则表达式模式的字符串
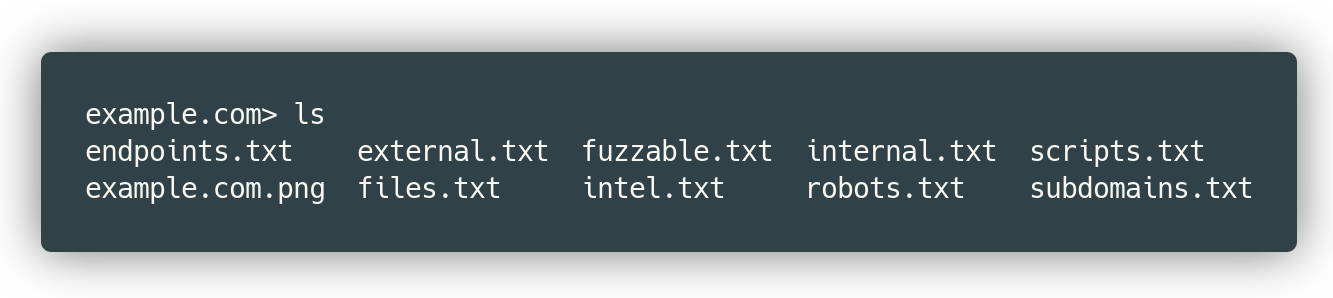
提取的信息按下图方式保存。
多线程爬取
大多数浮于互联网表面的工具都没有正确使用多线程,它们要么为线程提供一个项目列表,这会导致多个线程访问同一个项目,或者只是放置一个线程锁定并最终使多线程无效。
如何使用
1 | |
仅抓取单个网站
选项 -u 或 –url,使用示例:
1 | |
抓取深度
选项 -l 或 –level,默认深度为2,使用示例:
1 | |
通过该选项,用户可以设置抓取的递归限制,例如,深度为2意思是Photon会从主页和子页。
线程数
选项 -t 或 –threads,默认线程数为2,使用示例:
1 | |
该选项可以对目标进行并发请求,-t选项可用于指定要进行的并发请求数量。值得注意的是,虽然多线程可以加速抓取,但是也可能会触发安全机制,此外,线程数过多,也有可能使小型网站宕机。
每个HTTP请求间的延迟
选项 -d 或 –delay,默认为0,使用示例:
1 | |
该选项可以指定每个HTTP(S)请求之间间隔的秒数。有效值是int,例如1表示1秒。
超时
选项 –timeout,默认为5,使用示例:
1 | |
该选项指定HTTP(S)请求等待多长时间即为超时。
Cookies
选项 -c 或 –cookies,默认为 no cookie header is sent,使用示例:
1 | |
该选项允许你在非ninja模式下为发出的每个HTTP请求添加Cookie header,主要用于目标网站需要基于Cookie验证的情形。
指定输出目录
选项 -o 或 –output,默认为 目标域名,使用示例:
1 | |
Photon将结果保存在以目标域名命名的目录中,但你可以使用此选项自定义目录。
排除特定url
选项 –exclude,使用示例:
1 | |
匹配指定正则表达式的网址将不会被抓取及显示在结果中。
指定子url
选项 -s 或 –seeds,使用示例:
1 | |
你可以使用此选项添加自定义子URL,要以逗号分隔。
指定user-agent(s)
选项 –user-agent,使用示例:
1 | |
你可以使用此选项使用自己的用户代理,以逗号分隔。此选项仅用于帮助用户在不修改默认user-agents.txt文件的情况下使用特定用户代理。
自定义正则表达式模式
选项 -r 或 –regex,使用示例:
1 | |
通过使用此选项指定正则表达式模式,可以在抓取期间提取字符串。
导出格式化结果
选项 -e 或 –export
通过 -e 选项,你可以指定要保存文件的输出格式,使用示例:
1 | |
目前支持的格式:json
跳过数据提取
选项: –only-urls,使用示例:
1 | |
该选项会跳过提取js文件等数据,当你只需要抓取目标时,该选项可以派上用场。
更新
选项 –update,使用示例:
1 | |
如果使用此选项,Photon会检查更新。如果有新的版本,Photon会下载并将更新文件合并到当前目录中,Photon不会覆盖其他文件。
转储DNS数据
选项 –dns,使用示例:
1 | |
创建显示目标域名的DNS数据的图像。目前不支持目标是子域。